Client-Server Model and HTTP
Learning Objectives
- You are familiar with the client-server model.
- You know what the internet is and how it relates to the client-server model.
- You are familiar with the HyperText Transfer Protocol (HTTP) and can identify parts of an HTTP request and an HTTP response.
Now that we have already worked a bit on client-side applications, let’s take a step back to look at what’s going on.
Internet and client-server model
The internet is a network of networks that use the TCP/IP protocol for communication. The core principle of the internet builds on the client-server model, in which servers provide resources and services to clients, as shown in Figure 1.

From an application point of view, clients are typically dependent on the servers. Clients request services or resources from servers, while servers share their resources but clients typically do not.
The World Summit on Information Society in 2003 highlighted that everyone should have the possibility for creating, accessing, using, and sharing information and knowledge.
This, in part, is also related to internet access. The United Nations has condemned disrupting or limiting internet access and different countries take their responsibility in ensuring access to internet for all differently. As an example, Finland has declared the availability of internet as a basic right.
Layers of client-server applications
In practice, there are layers of client-server applications, and the same component can act as a client in one interaction and as a server in another. In our case, in the walking skeleton, we have the following interactions:
- User — Client-Side Application (Svelte)
- The user is the client.
- The web server hosting the Svelte application is the server.
- User makes a request using the browser to retrieve the Svelte application.
- Client-Side Application (Svelte) — Server-Side Application (Deno)
- The Svelte Application (in the browser) becomes the client.
- The Deno API server is the server.
- When the user interacts with the client-side application, the client-side application can make requests to the server-side applications to retrieve data.
- Server-Side Application (Deno) — Database (PostgreSQL)
- The Deno server is the client.
- The PostgreSQL database server is the server.
- When a request is made to the Deno server that requires data from the database, the Deno server makes a request to the PostgreSQL database server to retrieve or store data.
This overall structure is shown in Figure 2 below.
HyperText Transfer Protocol
Communication over TCP/IP is done using HyperText Transfer Protocol (HTTP), which is at the core of (almost) all web applications. HTTP defines the structure of messages that are sent between the client and the server.
This holds for the communication between the user who uses a browser and interacts with the client-side application, and the communication between the client-side application and the server-side application. However, the communication between the server-side application and the database server is typically done using a different protocol, such as PostgreSQL protocol for PostgreSQL databases.
HTTP is based on the request-response method, where a client initiates a request, and the server responds to the request. Unless a client has made a request, the server does not send any data to the client. Figure 3 below shows a simple example of a client making an HTTP GET request to the server, and the server responding with an HTTP response that contains status code 200 (OK) and some content.
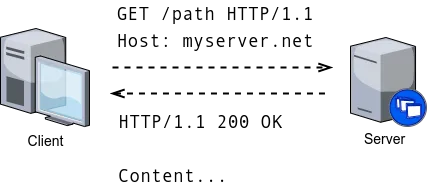
HTTP messages are text-based. Each message consists of rows that form a header and a set of optional rows that form a body. The body is not mandatory. The structure of the request and response messages is described below.
HTTP request structure
The first row of an HTTP request contains a request method, an identifier of the requested resource, and an indicator of the HTTP protocol. The subsequent rows may contain additional header rows, where each row has one header-value pair.
After headers, there is an empty line, which is followed by an optional request body that has data that is sent to the server. An HTTP request is ended with two line breaks.
request-method /path/to/resource HTTP/versionheader1: value1header2: value2header3: value3
optional body with contentHTTP methods GET and POST are the most common, where GET is used to ask for a resource from a server, while POST is used for sending data to the server. In practice, when you type in an address to a browser and hit enter, the browser makes a GET request to the server that hosts the resource.
GET requests should be idempotent, i.e. GET requests should not change the state of the server. POST requests do not have to be idempotent.
The example below outlines a simple GET request with no headers.
GET / HTTP/1.0The above example contains a GET request that asks for the resource at the root path of the server (/), using HTTP protocol version 1.0.
The resource identifier can be more complex, including a path, query parameters, and an anchor. The path is the part of the URI that comes after the domain name (e.g. /news/index.html). Query parameters come after a question mark and are used to provide additional information on what is being requested (e.g. /news/index.html?limit=10), and an anchor comes after a hash and is used to point to a specific part of a resource (e.g. /news/index.html#newest).
Some other commonly used methods are:
- DELETE: used to request the removal of a resource
- HEAD: used to request the header information of a resource, without the resource itself
- OPTIONS: used to request information about the communication options available for a resource
The resource identifier in the HTTP request does not contain the server address, but just the identifier of the resource. When data is sent over the HTTP protocol, a connection has already been established between the client and the server using TCP/IP. Thus, there is in principle no need to tell the address of the server in the HTTP request.
However, due to the increased use of virtual servers, where multiple servers can be hosted on the same physical server, the server address is needed. HTTP protocol version 1.1 introduced a Host header that must be included in the HTTP request. The value of the Host header is the server name. This way, even if an IP address has multiple servers — which each could have their own domain name such as www.example.com and api.example.com — the specific server to which the request is meant for can be determined.
For example, when a client makes a GET request to the address https://fitech101.aalto.fi/en, the first two lines of the HTTP request would be as follows.
GET /en HTTP/1.1Host: fitech101.aalto.fiHTTP response structure
The server returns — or should return — an HTTP response for every HTTP request. The first row of an HTTP response contains the protocol version, a status code, and a textual clarification of the status code.
This is followed by a set of headers each on its own line, similar to the HTTP request. The headers are followed by an empty line and a body of the response, which again similar to the HTTP request, is not mandatory.
HTTP/version status-code status-code-clarificationheader1: valueheader2: value
optional body with contentA simple response that tells that the request was received and all is well would be as follows. The response uses the status code 200, which translates to “OK”.
HTTP/1.1 200 OKHTTP status codes are numeric representations that the server can use to indicate how the processing of the request went, and whether there are any (pre-specified) actions that the client (in this case, typically browser) should take.
The status codes can be divided into five high-level categories which are as follows.
- 1**: Information messages (e.g. 100 “Continue”)
- 2**: Successful events (e.g. 200 “OK”)
- 3**: Additional actions required from the client (e.g. 301 “Moved Permanently”, which often is accompanied by a header that tells the new location, which the client then can retrieve)
- 4**: Error in the request or other issues (e.g. 401 “Not Authorized” and 404 “Not Found”)
- 5**: Error on the server e.g. 500 “Internal Server Error”)
A list of all HTTP-status codes is found on Wikipedia at https://en.wikipedia.org/wiki/List_of_HTTP_status_codes. Alternatively, you may e.g. take a peek at HTTP Cats or HTTP Status Dogs.
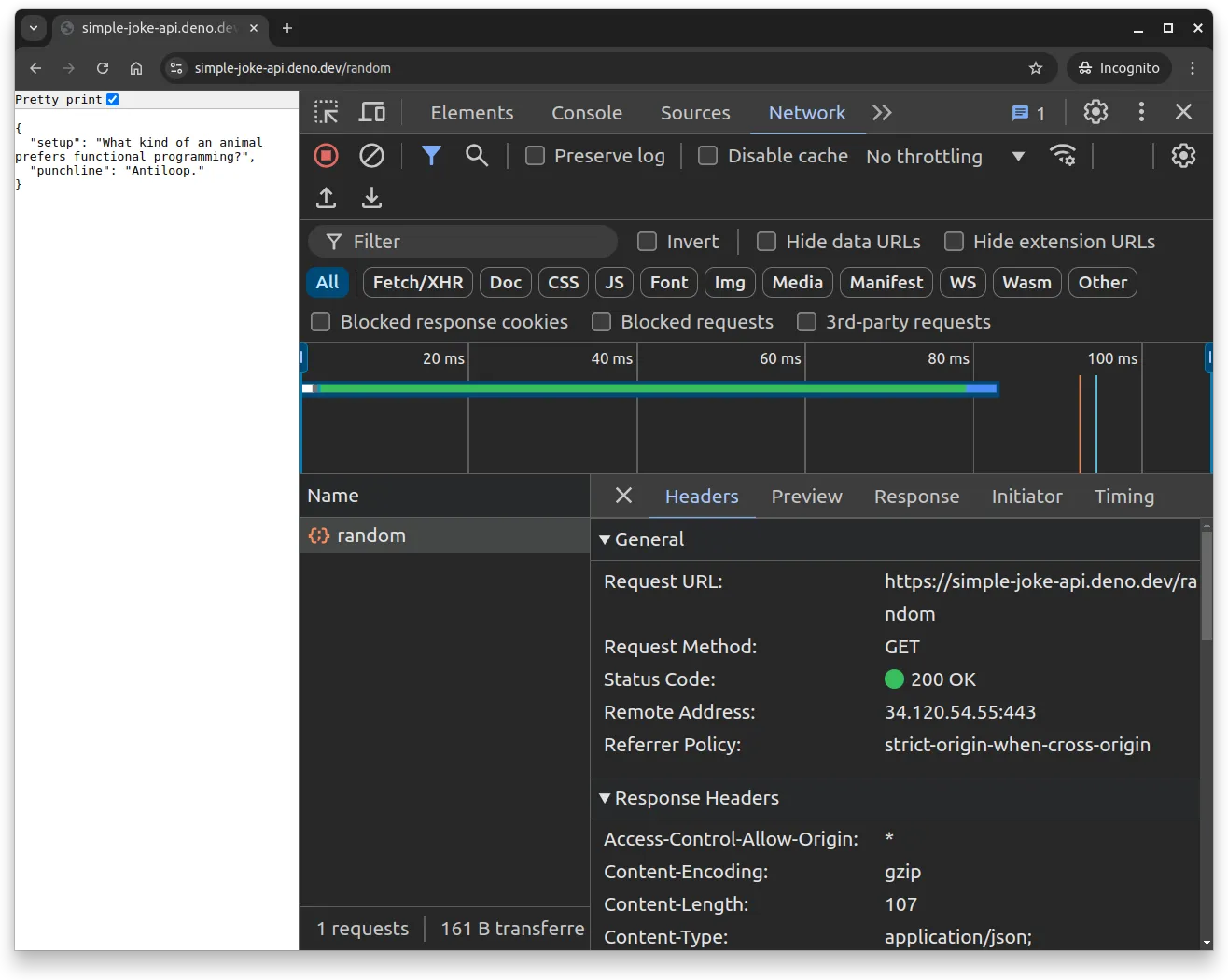
It is possible to also study the requests and responses using the developer console of a browser. In Chrome, you can open the developer console by pressing F12 and then selecting the Network tab. As an example, Figure 3 below shows the network tab in Chrome when visiting the address https://simple-joke-api.deno.dev/random. Some of the response headers are not visible in the image though.
HTTP uses text-based communication
Communication over HTTP is text-based. This means that the messages are human-readable, and users with access to the network over which the messages are sent can study the messages.
Due to this, it is important to use secure connections when transmitting sensitive information. Secure connections are established using the HyperText Transfer Protocol Secure (HTTPS) protocol, which is an extension of HTTP that uses encryption to secure the communication between the client and the server.
When using HTTPS, the connection is secured using a certificate. Current browsers support checking the status of the certificate — for example, in Chrome, there’s an icon on the left-hand side of the address bar and clicking the icon allows checking the certificate details.
HTTP protocols
There are newer HTTP variants, including HTTP/2 and HTTP/3, which both aim to improve the performance. While HTTP and HTTP/2 are based on TCP protocol, HTTP/3 works over User Datagram Protocol using QUIC. In the newer protocols, the structure of the messages is similar to the original HTTP, although the way the messages are sent and received is different.
In the context of this course, we do not distinguish between the HTTP versions, as the key concepts are the same across the different versions.
Differences between the protocols are more relevant when building high-performance applications, which is beyond the scope of this course. These differences are studied in the course Designing and Building Scalable Web Applications.
HTTP and retrieving a web page with a browser
Although we have mainly discussed individual HTTP requests and responses, it is important to keep in mind that in practice, retrieving a web page typically involves multiple requests and responses. When a user enters a URL in the address bar of a browser, the browser makes an HTTP request to the server that hosts the resource. The server responds with an HTTP response that contains the content of the resource.
If the content is an HTML-document, the browser interprets and renders the content, showing the content to the user. While interpreting the content, the browser also detects linked resources such as images, style files, and scripts. For each linked resource, the browser automatically makes a new request to the server.
Retrieving a single web page might in reality consist of the browser making hundreds of requests, even though for the user it might seem that only a single address is visited.
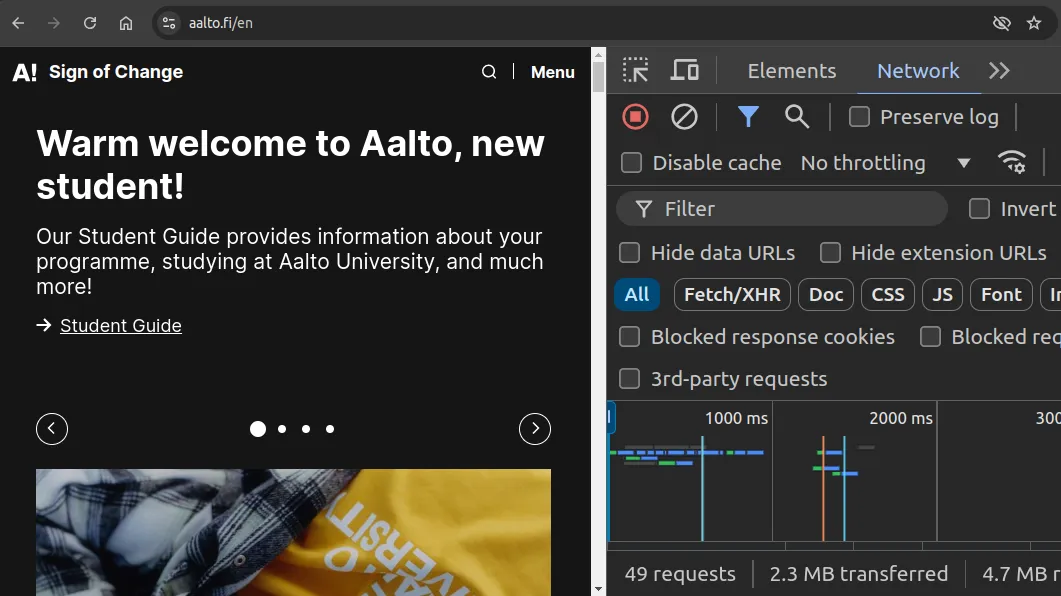
For example, when we open up the address https://aalto.fi/en, the browser makes almost 50 requests to load and show the content, as shown in Figure 5 below. The requests include the main HTML-document, style files, scripts, images, and other resources.
Summary
In summary:
- The internet is a network of networks. The core principle of the internet builds on the client-server model, in which servers provide resources and services to clients.
- The roles of client and server can be layered. The same component can act as a client in one interaction and as a server in another.
- Web applications use the HyperText Transfer Protocol (HTTP) for communication between clients and servers.
- HTTP messages are text-based. Each message consists of rows that form a header and a set of optional rows that form a body.
- An HTTP request is initiated by a client and contains a request method, an identifier of the requested resource, and the HTTP protocol version. The request may also contain additional headers and an optional body.
- An HTTP response is sent by the server in response to a request. The response contains the HTTP protocol version, a status code, a textual clarification of the status code, headers, and optionally a body.
- Secure communication uses HTTPS, which encrypts the messages exchanged between clients and servers.
AI Study Aid
Create a chapter diagram
We're looking into to what extent AI-generated diagrams could help with studying.
Use this study aid to generate an AI-generated visual summary of the material you just studied.
Each diagram style emphasizes the content in a different way, so you can choose the focus
that feels most useful.
Using the diagram generator is voluntary and does not affect your course progress. We encourage
you to try it out and see if it helps, but it's totally up to you! Your answers help us understand
how to make better study aids in the future.